Kubernetes Backup Solution, Kasten을 이용하여 Kube Application 복구 테스트 내역을 공유해 드립니다.
백업/복구 케이스 사례
- 사용자 실수 등으로 Grafana 대시보드 삭제 시 이전 시점 복구
- 시스템 이상 등으로 인한 Local Kube Cluster pvc, pod 삭제 시 복구
: 원격 public 클라우드(EKS) 복구 검증
각 상황 별 백업 및 복구 시간 그리고 원격지 DR 센터 운영을 위한 S3 및 EKS/VM 비용, 예상 RTO/RPO 내용까지 같이 포함 하였습니다.
Kasten 설치, 설정 등의 자세한 사항은 이전 포스팅을 참조 바랍니다.
Grafana 대시보드 복구
먼저 대시보드 삭제 전 현재 시점 기준으로 백업을 실행 합니다.
Policy - monitoring(Grafana) namespace 백업 정책 선택 - ‘run once’ 실행


snapshot 기반 백업을 수행하여 기존 서비스 i/o 성능 영향을 최소화 합니다. 백업 수행 시간 1min, 4 sec 소요.

이제 Grafana 대시보드 중 하나를 삭제합니다.
대시보드 - 우측 상단 Dashboard settings 선택
대시보드 삭제가 완료되었습니다. 이제 Kasten 이용하여 삭제된 대시보드를 복구 하겠습니다.
Kasten 메인화면 - Application - monitoring app - restore 선택

복구 시점 선택

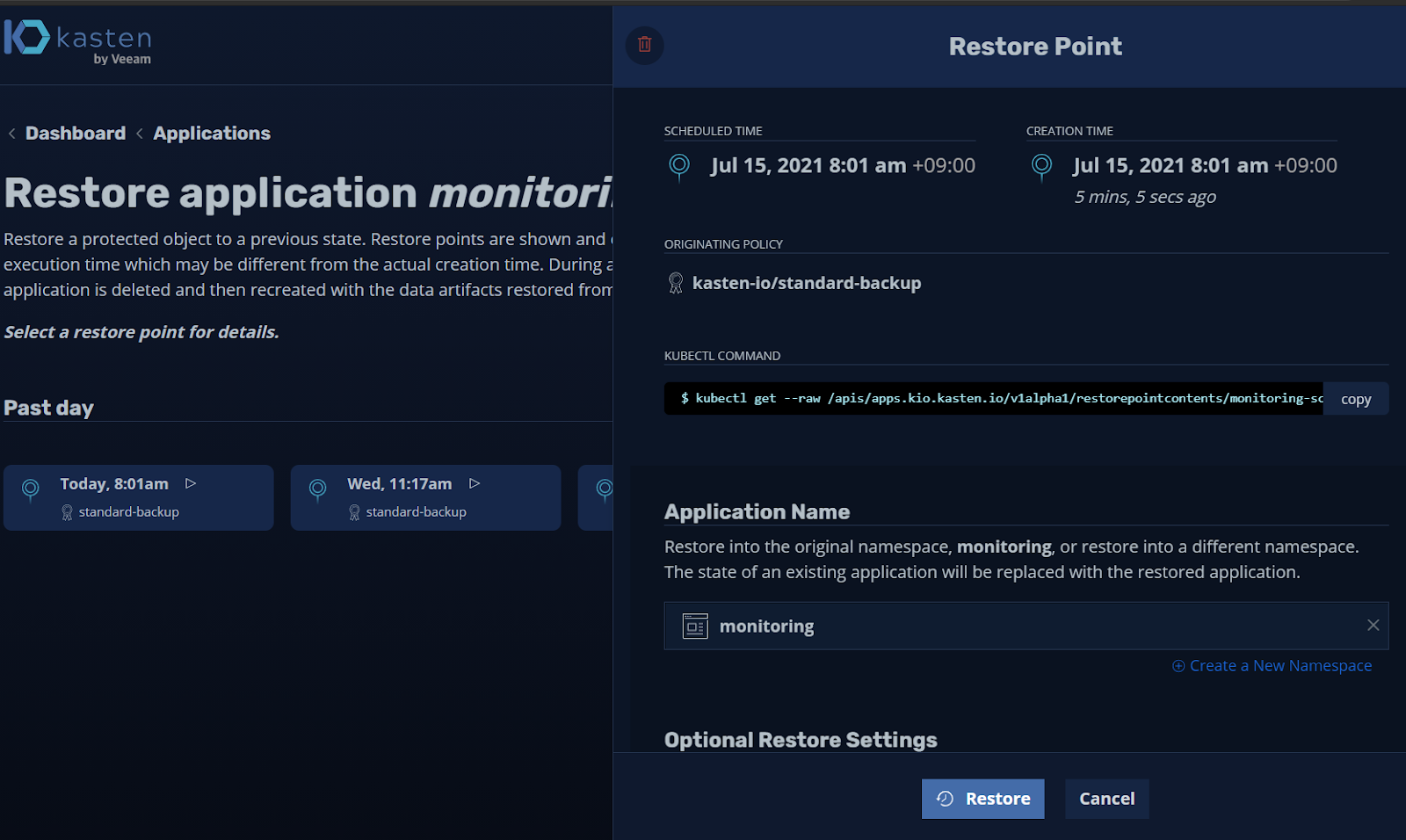
복구 옵션으로 기존 동일 namespace 혹은 신규 namespace 생성 등 선택이 가능합니다. 이번 예제는 기존과 동일한 namespace로 하겠습니다.

복구 대상 Artifacts(Kube Object) 확인
- 상황에 따라 복구할 대상을 선택 할 수 있습니다. 예를 들어 기존 POD는 그대로 두고 PVC 데이터만 복구 할 수 있습니다. 많은 경우 데이터만 복구 하는 게 유용한 옵션입니다.

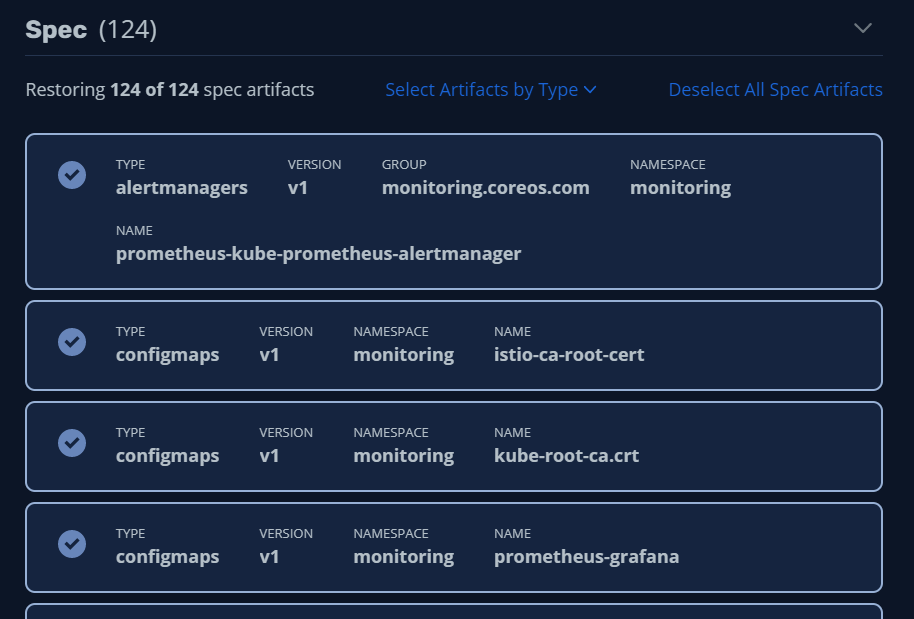
본 예제에서는 2개 데이터 + 124 artifacts 전체를 복구합니다.

복구 현황 확인이 가능합니다.

아래와 같이 복구가 시작되면 기존 PVC가 삭제되고 새로운 PVC를 생성합니다.
[spkr@erdia22 dynamic-provisioning (ubuns:monitoring)]$ k get pvc -w
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
prometheus-grafana Bound pvc-efa545a2-3234-493d-af4d-2b6359c1bb5d 10Gi RWO rook-ceph-block 20h
prometheus-prometheus-kube-prometheus-prometheus-db-prometheus-prometheus-kube-prometheus-prometheus-0 Bound pvc-2aaba151-5650-4ca6-92b5-104322f0c4be 50Gi RWO rook-ceph-block 20h
prometheus-prometheus-kube-prometheus-prometheus-db-prometheus-prometheus-kube-prometheus-prometheus-0 Terminating pvc-2aaba151-5650-4ca6-92b5-104322f0c4be 50Gi RWO
rook-ceph-block 20h
prometheus-prometheus-kube-prometheus-prometheus-db-prometheus-prometheus-kube-prometheus-prometheus-0 Terminating pvc-2aaba151-5650-4ca6-92b5-104322f0c4be 50Gi RWO
rook-ceph-block 20h
prometheus-grafana Terminating pvc-efa545a2-3234-493d-af4d-2b6359c1bb5d 10Gi RWO
rook-ceph-block 20h
prometheus-grafana Terminating pvc-efa545a2-3234-493d-af4d-2b6359c1bb5d 10Gi RWO
rook-ceph-block 20h
prometheus-grafana Pending
rook-ceph-block 0s
prometheus-grafana Pending
rook-ceph-block 0s
prometheus-prometheus-kube-prometheus-prometheus-db-prometheus-prometheus-kube-prometheus-prometheus-0 Pending
rook-ceph-block 0s
prometheus-prometheus-kube-prometheus-prometheus-db-prometheus-prometheus-kube-prometheus-prometheus-0 Pending
rook-ceph-block 0s
prometheus-grafana Pending pvc-99387e00-947b-4332-84ce-ae2676d8d4ec 0
rook-ceph-block 1s
prometheus-grafana Bound pvc-99387e00-947b-4332-84ce-ae2676d8d4ec 10Gi RWO
rook-ceph-block 1s
prometheus-prometheus-kube-prometheus-prometheus-db-prometheus-prometheus-kube-prometheus-prometheus-0 Pending pvc-5603f6b0-833a-408c-8da4-9e09c117deba 0
rook-ceph-block 1s
prometheus-prometheus-kube-prometheus-prometheus-db-prometheus-prometheus-kube-prometheus-prometheus-0 Bound pvc-5603f6b0-833a-408c-8da4-9e09c117deba 50Gi RWO
rook-ceph-block 1s동일하게 POD도 재생성됩니다.
[spkr@erdia22 ~ (ubuns:monitoring)]$ kgp -w
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
alertmanager-prometheus-kube-prometheus-alertmanager-0 2/2 Running 0 20h 10.233.94.206 ubun20-3 <none> <none>
prometheus-grafana-54d744489-fpmlh 2/2 Running 0 20h 10.233.94.208 ubun20-3 <none> <none>
prometheus-kube-prometheus-operator-84c6b8984c-mgljf 1/1 Running 0 20h 10.233.94.205 ubun20-3 <none> <none>
prometheus-kube-state-metrics-fcd578d77-fqjhs 1/1 Running 0 20h 10.233.94.204 ubun20-3 <none> <none>
prometheus-prometheus-kube-prometheus-prometheus-0 2/2 Running 1 20h 10.233.94.207 ubun20-3 <none> <none>
prometheus-prometheus-node-exporter-9mmk2 1/1 Running 0 21h 172.17.29.63 ubun20-3 <none> <none>
prometheus-prometheus-node-exporter-pnc26 1/1 Running 0 21h 172.17.29.61 ubun20-1 <none> <none>
prometheus-prometheus-node-exporter-xvq5n 1/1 Running 0 21h 172.17.29.62 ubun20-2 <none> <none>
prometheus-kube-prometheus-operator-84c6b8984c-mgljf 1/1 Terminating 0 20h 10.233.94.205 ubun20-3 <none> <none>
prometheus-grafana-54d744489-fpmlh 2/2 Terminating 0 20h 10.233.94.208 ubun20-3 <none> <none>
prometheus-prometheus-kube-prometheus-prometheus-0 2/2 Terminating 1 20h 10.233.94.207 ubun20-3 <none> <none>
prometheus-kube-prometheus-operator-84c6b8984c-mgljf 1/1 Terminating 0 20h 10.233.94.205 ubun20-3 <none> <none>
prometheus-grafana-54d744489-fpmlh 2/2 Terminating 0 20h 10.233.94.208 ubun20-3 <none> <none>
prometheus-prometheus-kube-prometheus-prometheus-0 2/2 Terminating 1 20h 10.233.94.207 ubun20-3 <none> <none>
prometheus-kube-prometheus-operator-84c6b8984c-mgljf 0/1 Terminating 0 20h 10.233.94.205 ubun20-3 <none> <none>
prometheus-grafana-54d744489-fpmlh 0/2 Terminating 0 20h 10.233.94.208 ubun20-3 <none> <none>
prometheus-prometheus-kube-prometheus-prometheus-0 0/2 Terminating 1 20h 10.233.94.207 ubun20-3 <none> <none>
prometheus-kube-prometheus-operator-84c6b8984c-mgljf 0/1 Terminating 0 20h 10.233.94.205 ubun20-3 <none> <none>
prometheus-kube-prometheus-operator-84c6b8984c-mgljf 0/1 Terminating 0 20h 10.233.94.205 ubun20-3 <none> <none>
prometheus-grafana-54d744489-fpmlh 0/2 Terminating 0 20h 10.233.94.208 ubun20-3 <none> <none>
prometheus-grafana-54d744489-fpmlh 0/2 Terminating 0 20h 10.233.94.208 ubun20-3 <none> <none>
prometheus-prometheus-kube-prometheus-prometheus-0 0/2 Terminating 1 20h 10.233.94.207 ubun20-3 <none> <none>
prometheus-prometheus-kube-prometheus-prometheus-0 0/2 Terminating 1 20h 10.233.94.207 ubun20-3 <none> <none>
prometheus-kube-state-metrics-fcd578d77-fqjhs 1/1 Terminating 0 20h 10.233.94.204 ubun20-3 <none> <none>
alertmanager-prometheus-kube-prometheus-alertmanager-0 2/2 Terminating 0 20h 10.233.94.206 ubun20-3 <none> <none>
prometheus-kube-state-metrics-fcd578d77-fqjhs 1/1 Terminating 0 20h 10.233.94.204 ubun20-3 <none> <none>
alertmanager-prometheus-kube-prometheus-alertmanager-0 2/2 Terminating 0 20h 10.233.94.206 ubun20-3 <none> <none>
prometheus-kube-state-metrics-fcd578d77-fqjhs 0/1 Terminating 0 20h 10.233.94.204 ubun20-3 <none> <none>
alertmanager-prometheus-kube-prometheus-alertmanager-0 0/2 Terminating 0 20h 10.233.94.206 ubun20-3 <none> <none>
alertmanager-prometheus-kube-prometheus-alertmanager-0 0/2 Terminating 0 20h 10.233.94.206 ubun20-3 <none> <none>
alertmanager-prometheus-kube-prometheus-alertmanager-0 0/2 Terminating 0 20h 10.233.94.206 ubun20-3 <none> <none>
prometheus-kube-state-metrics-fcd578d77-fqjhs 0/1 Terminating 0 20h 10.233.94.204 ubun20-3 <none> <none>
prometheus-kube-state-metrics-fcd578d77-fqjhs 0/1 Terminating 0 20h 10.233.94.204 ubun20-3 <none> <none>
prometheus-kube-state-metrics-fcd578d77-gzrz5 0/1 Pending 0 0s <none> <none> <none> <none>
prometheus-kube-state-metrics-fcd578d77-gzrz5 0/1 Pending 0 0s <none> ubun20-3 <none> <none>
prometheus-grafana-54d744489-hwnkv 0/2 Pending 0 0s <none> <none> <none> <none>
prometheus-grafana-54d744489-hwnkv 0/2 Pending 0 0s <none> <none> <none> <none>
prometheus-kube-state-metrics-fcd578d77-gzrz5 0/1 ContainerCreating 0 0s <none> ubun20-3 <none> <none>
prometheus-kube-prometheus-operator-84c6b8984c-5rgzt 0/1 Pending 0 0s <none> <none> <none> <none>
prometheus-kube-prometheus-operator-84c6b8984c-5rgzt 0/1 Pending 0 0s <none> ubun20-3 <none> <none>
prometheus-kube-prometheus-operator-84c6b8984c-5rgzt 0/1 ContainerCreating 0 0s <none> ubun20-3 <none> <none>
prometheus-kube-state-metrics-fcd578d77-gzrz5 0/1 ContainerCreating 0 1s <none> ubun20-3 <none> <none>
prometheus-kube-prometheus-operator-84c6b8984c-5rgzt 0/1 ContainerCreating 0 1s <none> ubun20-3 <none> <none>
prometheus-prometheus-kube-prometheus-prometheus-0 0/2 Pending 0 0s <none> <none> <none> <none>
prometheus-prometheus-kube-prometheus-prometheus-0 0/2 Pending 0 0s <none> <none> <none> <none>
alertmanager-prometheus-kube-prometheus-alertmanager-0 0/2 Pending 0 0s <none> <none> <none> <none>
alertmanager-prometheus-kube-prometheus-alertmanager-0 0/2 Pending 0 0s <none> ubun20-3 <none> <none>
alertmanager-prometheus-kube-prometheus-alertmanager-0 0/2 ContainerCreating 0 0s <none> ubun20-3 <none> <none>
alertmanager-prometheus-kube-prometheus-alertmanager-0 0/2 ContainerCreating 0 1s <none> ubun20-3 <none> <none>
prometheus-kube-prometheus-operator-84c6b8984c-5rgzt 1/1 Running 0 2s 10.233.94.213 ubun20-3 <none> <none>
prometheus-kube-state-metrics-fcd578d77-gzrz5 0/1 Running 0 2s 10.233.94.212 ubun20-3 <none> <none>
prometheus-grafana-54d744489-hwnkv 0/2 Pending 0 3s <none> ubun20-3 <none> <none>
prometheus-prometheus-kube-prometheus-prometheus-0 0/2 Pending 0 2s <none> ubun20-3 <none> <none>
prometheus-grafana-54d744489-hwnkv 0/2 Init:0/2 0 3s <none> ubun20-3 <none> <none>
prometheus-prometheus-kube-prometheus-prometheus-0 0/2 ContainerCreating 0 3s <none> ubun20-3 <none> <none>
alertmanager-prometheus-kube-prometheus-alertmanager-0 1/2 Running 0 4s 10.233.94.214 ubun20-3 <none> <none>
alertmanager-prometheus-kube-prometheus-alertmanager-0 2/2 Running 0 5s 10.233.94.214 ubun20-3 <none> <none>
prometheus-kube-state-metrics-fcd578d77-gzrz5 1/1 Running 0 10s 10.233.94.212 ubun20-3 <none> <none>
prometheus-grafana-54d744489-hwnkv 0/2 Init:0/2 0 17s <none> ubun20-3 <none> <none>
prometheus-grafana-54d744489-hwnkv 0/2 Init:1/2 0 18s 10.233.94.215 ubun20-3 <none> <none>
prometheus-grafana-54d744489-hwnkv 0/2 Init:1/2 0 19s 10.233.94.215 ubun20-3 <none> <none>
prometheus-grafana-54d744489-hwnkv 0/2 PodInitializing 0 21s 10.233.94.215 ubun20-3 <none> <none>
prometheus-grafana-54d744489-hwnkv 1/2 Running 0 21s 10.233.94.215 ubun20-3 <none> <none>
prometheus-grafana-54d744489-hwnkv 2/2 Running 0 23s 10.233.94.215 ubun20-3 <none> <none>
prometheus-prometheus-kube-prometheus-prometheus-0 0/2 ContainerCreating 0 24s <none> ubun20-3 <none> <none>
prometheus-prometheus-kube-prometheus-prometheus-0 1/2 Error 0 26s 10.233.94.216 ubun20-3 <none> <none>
prometheus-prometheus-kube-prometheus-prometheus-0 1/2 Running 1 27s 10.233.94.216 ubun20-3 <none> <none>
prometheus-prometheus-kube-prometheus-prometheus-0 2/2 Running 1 47s 10.233.94.216 ubun20-3 <none> <none>복구 시간은 아래와 같이 총 2min 18sec 소요되었습니다.

Grafana 페이지에서 확인해 보시면 아래와 같이 정상적으로 기존 대시보드가 복구 되었습니다.

Kasten을 이용하시면 Grafana 대시보드도 별다른 추가 설정없이 자동으로 백업 및 복구가 가능한 것을 확인 할 수 있습니다.
Kube CLI로 확인해 본바와 같이 기존 PVC와 POD가 삭제되고 신규 PVC와 POD가 생성되었습니다. 백업 및 복구 시간도 Snapshot 기반이라 각각 1min 4sec, 2min 18sec 으로 아주 양호 합니다. 물론 타 서비스 I/O 영향도 최소화 합니다.
다음으로 DR 용 원격지 Public Cloud Kube Cluster(EKS)로 복구 내역입니다. 테스트 대상 서비스는 MySQL DB가 포함된 wordpress 서비스 입니다.
[spkr@erdia22 dynamic-provisioning (ubuns:wordpress)]$ kgp
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
wordpress-5994d99f46-hwmg8 1/1 Running 0 21h 10.233.94.188 ubun20-3 <none> <none>
wordpress-mysql-6c479567b-cktdx 1/1 Running 0 21h 10.233.94.187 ubun20-3 <none> <none>
[spkr@erdia22 dynamic-provisioning (ubuns:wordpress)]$ k get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
mysql-pv-claim Bound pvc-6dca1c47-e9ca-44d3-bd0a-835410b0ecb8 20Gi RWO rook-ceph-block 21h
wp-pv-claim Bound pvc-4311987e-c9ec-4033-ac57-0eb25dfc6daf 20Gi RWO rook-ceph-block 21h서비스 삭제 전 kasten 백업을 수행합니다.
Kasten 메인페이지 - Policies - wordpress-backup 선택 - 백업 수행


백업 수행 시 원격지 DR 사이트에 백업 데이터 공유를 위하여 AWS S3 스토리지로 데이터 Export 되도록 설정 되었습니다. (kasten은 원격지 스토리지 백업 시 export 용어를 사용합니다.)
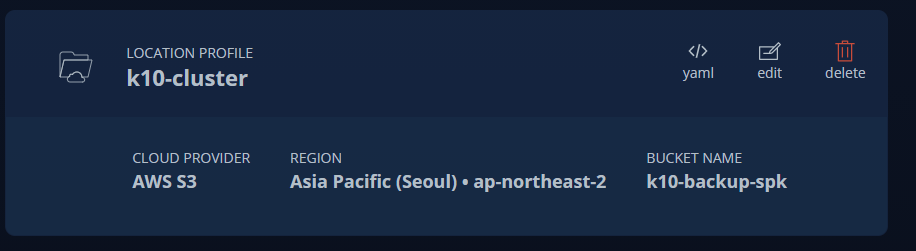
아래와 같이 메인페이지에서 Export 현황을 확인 가능합니다.

그럼, 기존 POD, PVC를 강제로 삭제 하겠습니다.
[spkr@erdia22 dynamic-provisioning (ubuns:wordpress)]$ k delete deployments.apps --all
deployment.apps "wordpress" deleted
deployment.apps "wordpress-mysql" deleted
[spkr@erdia22 dynamic-provisioning (ubuns:wordpress)]$ kgp
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
wordpress-5994d99f46-hwmg8 1/1 Terminating 0 21h 10.233.94.188 ubun20-3 <none> <none>
wordpress-mysql-6c479567b-cktdx 1/1 Terminating 0 21h 10.233.94.187 ubun20-3 <none> <none>
[spkr@erdia22 dynamic-provisioning (ubuns:wordpress)]$ k delete pvc --all
persistentvolumeclaim "mysql-pv-claim" deleted
persistentvolumeclaim "wp-pv-claim" deleted
[spkr@erdia22 dynamic-provisioning (ubuns:wordpress)]$ k get pvc,pod
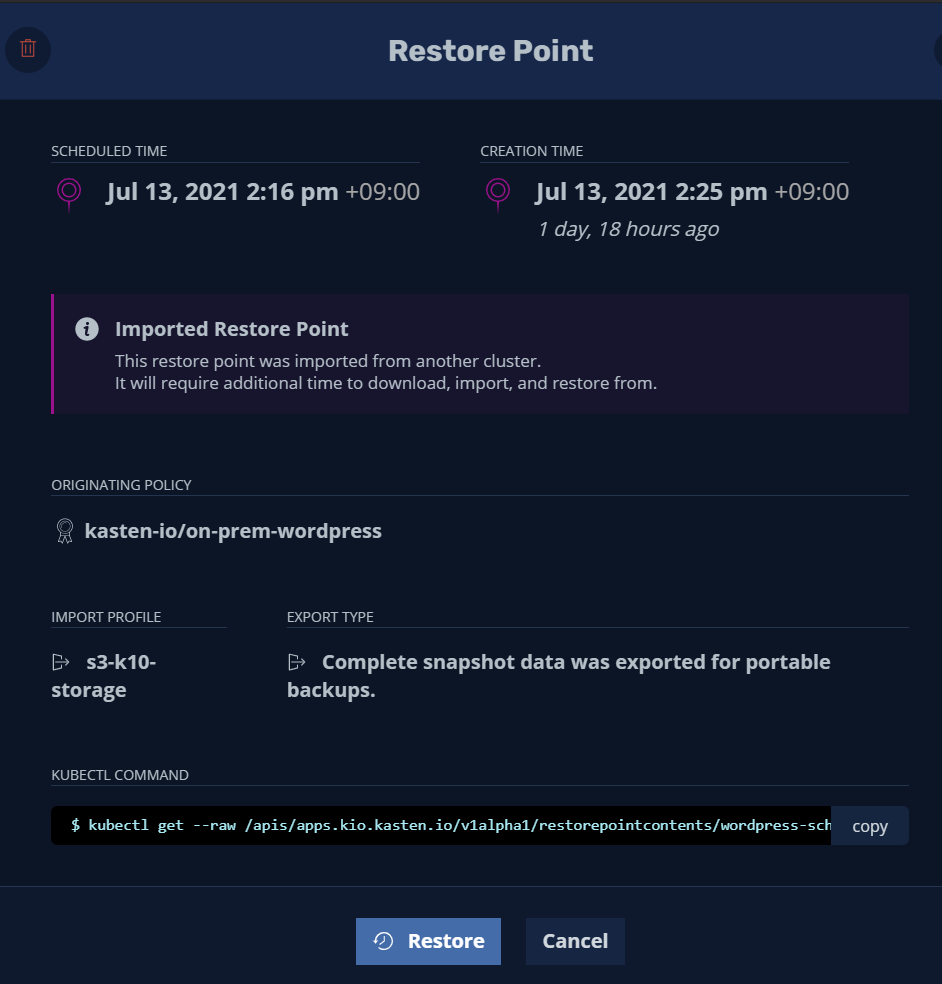
No resources found in wordpress namespace.이제 원격지 EKS Kube Cluster에서 해당 Export 된 백업 파일을 이용하여 wordpress 사이트를 복구 하겠습니다.
EKS에서도 아래와 같이 Kasten을 설치 하였습니다.

사전 세팅을 통하여 on-prem wordpress application 복구 설정을 완료 하였습니다. 이제 백업 export된 데이터를 사용 가능하도록 import 하겠습니다.
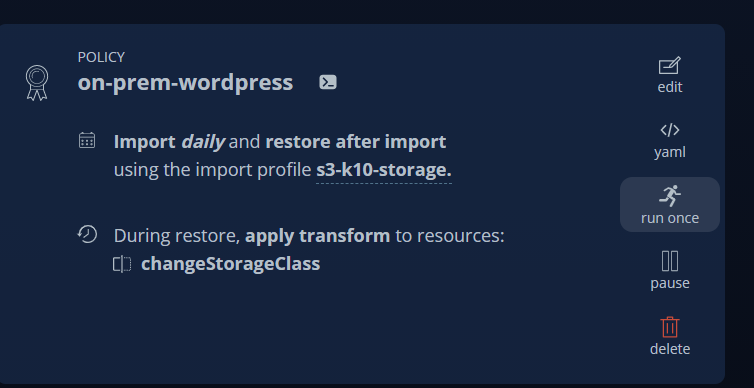
기존 데이터와 변경 사항이 없는 경우 아래와 같이 추가 시간이 소요되지 않습니다.

이제 Application 복구하겠습니다.
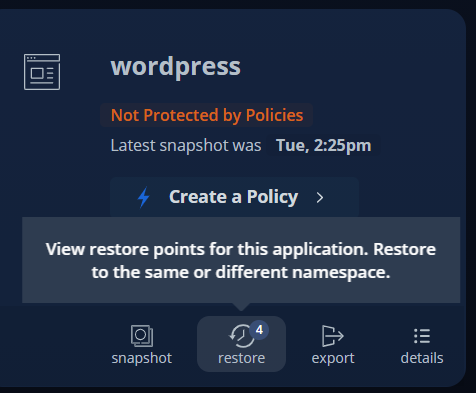
서로 다른 Kube cluster 간 storage class 이름이 상이하므로 on-prem에서 사용 중인 기존 rook-ceph-block 스토리지 클래스를 aws에서 사용 가능한 ebs-sc로 변경합니다.

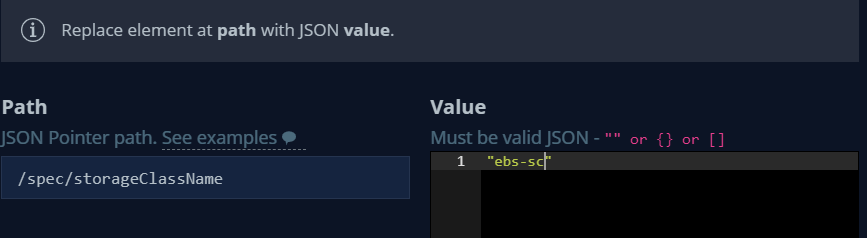
또한 on-prem 사용하는 rook-ceph-block 스토리지 클래스는 EKS에서 사용하지 않으므로 선택 해제 합니다.

복구를 시작하면 on-prem 복구와 유사하게 기존 PVC, POD를 삭제하고 새로운 PVC,POD가 생성됩니다.
[spkr@erdia22 ~ (kube@k10-kube.ap-northeast-2.eksctl.io:wordpress)]$ k get pvc -w
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
mysql-pv-claim Pending ebs-sc 0s
wp-pv-claim Pending ebs-sc 0s
mysql-pv-claim Pending ebs-sc 2s
mysql-pv-claim Pending ebs-sc 2s
wp-pv-claim Pending ebs-sc 3s
wp-pv-claim Pending ebs-sc 3s
mysql-pv-claim Pending pvc-820cc750-9554-4c9b-8522-045d908d724c 0 ebs-sc 5s
mysql-pv-claim Bound pvc-820cc750-9554-4c9b-8522-045d908d724c 20Gi RWO ebs-sc 5s
wp-pv-claim Pending pvc-6cb24767-77a2-4bf4-a425-dd925ce0fa55 0 ebs-sc 6s
wp-pv-claim Bound pvc-6cb24767-77a2-4bf4-a425-dd925ce0fa55 20Gi RWO ebs-sc 6s
[spkr@erdia22 ~ (kube@k10-kube.ap-northeast-2.eksctl.io:wordpress)]$ kgp -w
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
restore-data-84c2s 0/1 Pending 0 3m20s <none> <none> <none> <none>
restore-data-sdl2p 0/1 Pending 0 3m21s <none> <none> <none> <none>
restore-data-sdl2p 0/1 Terminating 0 4m3s <none> <none> <none> <none>
restore-data-84c2s 0/1 Terminating 0 4m2s <none> <none> <none> <none>
restore-data-sdl2p 0/1 Terminating 0 4m4s <none> <none> <none> <none>
restore-data-84c2s 0/1 Terminating 0 4m3s <none> <none> <none> <none>
restore-data-c4jtx 0/1 Pending 0 0s <none> <none> <none> <none>
restore-data-2w4xd 0/1 Pending 0 0s <none> <none> <none> <none>
restore-data-c4jtx 0/1 Pending 0 4s <none> ip-192-168-24-10.ap-northeast-2.compute.internal <none> <none>
restore-data-c4jtx 0/1 ContainerCreating 0 4s <none> ip-192-168-24-10.ap-northeast-2.compute.internal <none> <none>
restore-data-2w4xd 0/1 Pending 0 4s <none> ip-192-168-24-10.ap-northeast-2.compute.internal <none> <none>
restore-data-2w4xd 0/1 ContainerCreating 0 4s <none> ip-192-168-24-10.ap-northeast-2.compute.internal <none> <none>
restore-data-c4jtx 1/1 Running 0 13s 192.168.11.246 ip-192-168-24-10.ap-northeast-2.compute.internal <none> <none>
restore-data-2w4xd 1/1 Running 0 22s 192.168.20.191 ip-192-168-24-10.ap-northeast-2.compute.internal <none> <none>
restore-data-c4jtx 1/1 Terminating 0 28s 192.168.11.246 ip-192-168-24-10.ap-northeast-2.compute.internal <none> <none>
restore-data-2w4xd 1/1 Terminating 0 29s 192.168.20.191 ip-192-168-24-10.ap-northeast-2.compute.internal <none> <none>
wordpress-5994d99f46-8dr7p 0/1 Pending 0 0s <none> <none> <none> <none>
wordpress-mysql-6c479567b-2976h 0/1 Pending 0 0s <none> <none> <none> <none>
wordpress-5994d99f46-8dr7p 0/1 Pending 0 0s <none> ip-192-168-24-10.ap-northeast-2.compute.internal <none> <none>
wordpress-mysql-6c479567b-2976h 0/1 Pending 0 0s <none> ip-192-168-24-10.ap-northeast-2.compute.internal <none> <none>
wordpress-5994d99f46-8dr7p 0/1 ContainerCreating 0 0s <none> ip-192-168-24-10.ap-northeast-2.compute.internal <none> <none>
wordpress-mysql-6c479567b-2976h 0/1 ContainerCreating 0 0s <none> ip-192-168-24-10.ap-northeast-2.compute.internal <none> <none>
wordpress-mysql-6c479567b-2976h 1/1 Running 0 3s 192.168.7.103 ip-192-168-24-10.ap-northeast-2.compute.internal <none> <none>
wordpress-5994d99f46-8dr7p 1/1 Running 0 3s 192.168.17.136 ip-192-168-24-10.ap-northeast-2.compute.internal <none> <none>시간은 약 1min, 39sec 소요되었습니다.

[spkr@erdia22 ~ (kube@k10-kube.ap-northeast-2.eksctl.io:wordpress)]$ k get pvc,pod
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
persistentvolumeclaim/mysql-pv-claim Bound pvc-820cc750-9554-4c9b-8522-045d908d724c 20Gi RWO ebs-sc 6m48s
persistentvolumeclaim/wp-pv-claim Bound pvc-6cb24767-77a2-4bf4-a425-dd925ce0fa55 20Gi RWO ebs-sc 6m48s
NAME READY STATUS RESTARTS AGE
pod/wordpress-5994d99f46-8dr7p 1/1 Running 0 6m13s
pod/wordpress-mysql-6c479567b-2976h 1/1 Running 0 6m13s위와 같이 On-Prem Application을 정상적으로 EKS 상에서 복구가 가능합니다.
Kasten을 이용하여 DR을 구성하시면 위와 같이 시간과 비용 측면에서 효율적으로 운영이 가능합니다. 평소에 Local Cluster에서 원격지 S3 스토리지로 주기적으로 백업 데이터를 Export 하고, 원격지 EKS Cluster에서 1대 VM으로 최소한으로 EKS Cluster를 운영하거나 혹은 아예 클러스터를 운영하지 않다가 필요한 경우 EKS Cluster VM 인스턴스 수량을 증가 하거나 혹은 신규 EKS Cluster 생성하시면 됩니다.
이 경우 RPO(Recovery Point Objective)는 1시간 혹은 1일 단위이고 RTO(Recovery Time Objective)는 30분 이내 수준으로 유지가 가능합니다.

비용은 S3 비용, 1TB 기준 한 달 25$, VM 인스턴스 t4g.large 기준 (2core/8G) 한 달 50$, EKS 추가 비용 한 달 74$ 입니다. 한 달 기준 약 17만원(150$) 으로 굉장히 저렴하게 DR 센터 운영이 가능합니다. (물론 DR 센터를 실 운영 기준으로 여러 개 VM 인스턴스를 실행하면 추가 비용이 발생합니다.) 기존 VM 기반 원격지 DR 센터에 비하여 획기적으로 낮은 비용입니다. 속도도 비교할 수 정도로 빠르고 구성이 쉬운 DR 센터입니다.
이상으로 Kasten 이용한 Application 백업 및 원격 EKS Cluster 구성 방안을 공유해 드렸습니다.
'쿠버네티스 일반 > Kasten' 카테고리의 다른 글
| Kasten - Kubernetes 백업 및 복구 Demo (1) | 2021.08.05 |
|---|---|
| Veeam Kasten - On-Prem to Azure AKS 이전 (0) | 2021.06.28 |
| Kube 백업 - Veeam Kasten 테스트 내역 공유 (10) | 2021.06.23 |