AS-IS
통화 녹음, 문자 변환 앱 '스위치'를 서비스하는 아틀라스랩스는 현재 카프카를 운영 환경은 AWS MSK 매니지드 서비스를 사용하고 개발은 EC2, 스테이지는 AWS EKS에 사용 중이다.
스테이지 환경이기는 하지만 EKS에 카프카 올려서 사용하고 있는데, Bitnami 헬름 차트로 설치하였다. 다른 애플리케이션처럼 헬름을 사용하면 (당연하게도) 설치는 잘되고 카프카 메시지도 정상적으로 보내지고 받아지니 아무 생각없이 사용하고 있다.
문제는 별 생각없이 설치하고 기본 기능만 잘 동작하면 그냥 사용한다는 거다. DB도 마찬가지이지만 바쁘고 담당자가 없다는 이유로 운영 환경은 그냥 매니지드 서비스 맡기고 스테이지 환경은 돌아가기만 하면 된다는 안일한 생각으로 운영하고 있다. Failover 테스트도 안하고 스트레스 부하 테스트도 하지 않는다. (나만 그런 것은 아니겠지 ^^)
규모가 크지 않은 회사에 1인 데브옵스라 이런 '중요하지만 바쁘지 않는 일은' 항상 굳이 중요하지 않지만 급한 일에 항상 우선 순위가 밀린다. 그러고 하지 않는다. 실제 규모가 크지 않기에 빡세게 사용하지 않으면 카프카는 안정적으로 동작하는 것 같아, 머 장애가 없으면 된다는 마음이기는 하다. 하지만 마음 한 구석은 무겁다. 카프카도 알고 Elastic도 알고 DB, Redis도 알아야 하는데...
파드 하나가 내려가도 이상 없이 잘 동작할까? 또는 노드가 내려가도 실시간으로 메시지 주고 받는데 이상 없을까? 심지어 나는 스테이지 환경은 스팟 인스턴스 사용하고 있어서 2~3일에 한번꼴은 노드가 죽었다 살았다 하는데 데이터가 깨지고 그러지는 않을까 라는 염려가 항상된다. 물론, 만약 테스트가 잘된다면 운영 환경도 굳이 추가 비용을 내고 매니지드 MSK 서비스를 사용해야 하는 의문도 있다.
TO-BE
다행히 가시다님이 쿠버네티스 오퍼레이터 스터디를 하면서 카프카도 같이 다룬다. (항상 감사하는 갓갓갓 가시다님) 스터디에 배운 내용을 실습으로 되풀이해본다. 실 서비스에 사용하는 거라 도움이 많이 된다.
마음에 짐 같았던 카프카 설치, 메시지 전송, Failover 테스트 실습을 해 보았다.
실습 내역
- Strimzi Kafka Operator 이용 카프카 클러스터 설치
- 메세지 produce 및 consume + 신기한 Kafka messages CRD 확인
- kafka 고가용성 테스트 - 노드 내려가도 메시지 주고받는 거 이상없는지
전용 kafka 네임스페이스 만든다. kafka 네임스페이스에 설치한다.
$ (⎈ |kr-stage-new:kube-system) k create ns kafka
namespace/kafka created
$ (⎈ |kr-stage-new:kube-system) k ns kafka
Context "kr-stage-new" modified.
Active namespace is "kafka".그럼 strimzi kafka operator를 설치한다. Strimzi는 오픈 소스 커뮤니티로 쿠버네티스 환경에서 카프카를 사용하기 위한 오퍼레이터를 만들고 있다.
Join Us
Grow with Strimzi Everyone can join the Strimzi community and grow with it. It doesn’t matter what your skills are because you can contribute in many different ways. It also doesn’t matter whether you have just a few minutes to say `Hi` or you can spen
strimzi.io
쿠버네티스 Operator란 애플리케이션 설치와 관리를 쉽게 하기 위해서 사용자가 직접 만든 전용 도구 정도로 이해하고 있다.
헬름 파일을 이용해서 설치할 때 난 아래와 같이 로컬에 헬름 파일을 다운(helm pull)받고 설치하는 것을 추천한다. 헬름 차트 버전과 헬름 템플릿 변수 파일 이력 관리 용도로 낫기 때문이다.
# 먼저 repo를 추가하고 소스를 내려받습니다.
$ (⎈ |kr-stage-new:kafka) helm repo add strimzi https://strimzi.io/charts/
$ (⎈ |kr-stage-new:kafka) helm pull strimzi/strimzi-kafka-operator
$ (⎈ |kr-stage-new:kafka) tar xvfz strimzi-kafka-operator-helm-3-chart-0.29.0.tgz
# tar 파일은 지우고 헬름 템플릿 변수 파일을 copy 합니다.
$ (⎈ |kr-stage-new:kafka) rm -rf strimzi-kafka-operator-helm-3-chart-0.29.0.tgz
$ (⎈ |kr-stage-new:kafka) cd strimzi-kafka-operator
$ (⎈ |kr-stage-new:kafka) cp values.yaml my-values.yaml카프카 클러스터 설치가 아닌 카프카 operator만 설치하는 거라 my-vaules.yaml 파일은 별다른 옵션 수정없이 바로 설치한다.
$ (⎈ |kr-stage-new:kafka) helm install kafka-operator -f my-values.yaml .
NAME: kafka-operator
LAST DEPLOYED: Fri Jun 10 14:57:18 2022
NAMESPACE: kafka
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
Thank you for installing strimzi-kafka-operator-0.29.0
To create a Kafka cluster refer to the following documentation.
https://strimzi.io/docs/operators/latest/deploying.html#deploying-cluster-operator-helm-chart-str설치가 완료되면 카프카 관련 CRD 리소스를 확인할 수 있다. CRD - CustomResourceDefinition - 란 벤더(또는 사용자)가 쿠버네티스 API 확장 기능을 사용해서 만든 커스텀 리소스다. deployment, pod 등 쿠버네티스 기본으로 제공하는 리소스가 아닌 Custom으로 만든 리소스 정도라고 이해하고 있다. kafka 관련 다양한 리소스가 만들어졌다.
$ (⎈ |kr-stage-new:kafka) k get crd|grep kafka
kafkabridges.kafka.strimzi.io 2022-06-10T05:57:15Z
kafkaconnectors.kafka.strimzi.io 2022-06-10T05:57:15Z
kafkaconnects.kafka.strimzi.io 2022-06-10T05:57:14Z
kafkamirrormaker2s.kafka.strimzi.io 2022-06-10T05:57:15Z
kafkamirrormakers.kafka.strimzi.io 2022-06-10T05:57:15Z
kafkarebalances.kafka.strimzi.io 2022-06-10T05:57:15Z
kafkas.kafka.strimzi.io 2022-06-10T05:57:13Z
kafkatopics.kafka.strimzi.io 2022-06-10T05:57:14Z
kafkausers.kafka.strimzi.io 2022-06-10T05:57:14Z해당 CRD를 이용해서 카프카 클러스터를 만들 수 있다. 즉 카프카 클러스터도 하나의 쿠버네티스 리소스로 YAML 파일을 이용해서 만들 수 있다. 신기하다.
그럼 카프카 클러스터를 만들기 위해서 카프카 YAML 파일을 만든다. 카프카 YAML 파일은 아쉽게도(혹은 내가 아직 못 찾아서 그런지는 모르겠지만) 전체 옵션에 대한 상세한 설명은 찾을 수 없다. 오퍼레이터를 이용해서 설치하면 다른 애플리케이션도 그런데 전체 옵션 + 해당 옵션의 디폴트 설정 값을 찾기 어려운게 아쉽다.
다만 Strimzi 깃허브에 kafka 설치 관련 예제 파일이 있어서 해당 파일을 참조 하였다.
예제 참조
https://github.com/strimzi/strimzi-kafka-operator/tree/0.29.0/examples/kafka
GitHub - strimzi/strimzi-kafka-operator: Apache Kafka® running on Kubernetes
Apache Kafka® running on Kubernetes. Contribute to strimzi/strimzi-kafka-operator development by creating an account on GitHub.
github.com
내가 설치에 참조한 카프카 클러스터 YAML 파일이다.
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
version: 3.2.0
## 카프카 broker 3개 설정
replicas: 3
listeners:
- name: plain
port: 9092
type: internal
tls: false
- name: tls
port: 9093
type: internal
tls: true
config:
offsets.topic.replication.factor: 3
transaction.state.log.replication.factor: 3
transaction.state.log.min.isr: 2
## 메시지 replica 3개, 3벌 복제로 저장
default.replication.factor: 3
min.insync.replicas: 2
inter.broker.protocol.version: "3.2"
storage:
type: jbod
volumes:
- id: 0
type: persistent-claim
size: 100Gi
deleteClaim: false
zookeeper:
replicas: 3
storage:
type: persistent-claim
size: 100Gi
deleteClaim: false
entityOperator:
topicOperator: {}
userOperator: {}- spec.kafka.replicas: 3
3개의 broker pod를 만들어서 3중화 한다. 파드 혹은 노드 장애 시 failover 가능하다. - spec.kafka.config.default.replication.factor: 3
카프카 메시지 역시 3벌 복제되어 전송하도록 설정한다.
설치 시 여러 옵션을 설정하는 게 중요한데 오퍼레이터로 설치하면 헬름과 다르게 전체 옵션을 찾기가 쉽지 않다. 그나마 찾은게 아래 전체 옵션 리스트 정도이다. 너무 내용이 방대하고 보기가 불편해서 그냥 대충 보았다. 카프카 설치 시 옵션을 어떻게 설정해야 하는지 모르는게 문제인데, 이건 운영을 하면서 문제가 발생해야 알 듯하다. 많은 일이 그러하듯 경험이 필요한 일인가 싶다.
GitHub - strimzi/strimzi-kafka-operator: Apache Kafka® running on Kubernetes
Apache Kafka® running on Kubernetes. Contribute to strimzi/strimzi-kafka-operator development by creating an account on GitHub.
github.com
구성 내역을 간략하게 그림으로 표현하면 아래와 같다.
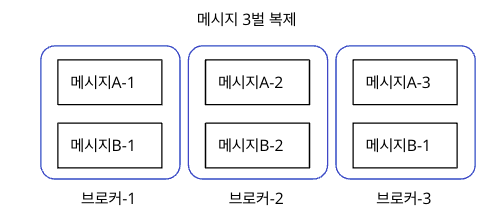
브로커는 카프카에서 메시지를 받는 서버 정도라고 생각하고 있다.
해당 설정으로 카프카를 설치한다.
## 설치 전에 PV를 사용하므로 default storage class 설정이 되어 있어야 한다.
$ (⎈ |ubun01:kafka) k get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
openebs-hostpath (default) openebs.io/local Delete WaitForFirstConsumer false 10m
## 특이하게 (혹은 고맙게도) 카프카를 YAML 파일로 설치한다.
$ (⎈ |kr-stage-new:kafka) k apply -f kafka-persistent.yaml
kafka.kafka.strimzi.io/my-cluster created
## strimzi operator부터 순차적으로 설치된다.
$ (⎈ |ubun01:kafka) k get pod -o wide -w
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
strimzi-cluster-operator-7c77f74847-jrpq4 0/1 Running 0 32s 10.233.87.7 ubun20-05 <none> <none>
my-cluster-zookeeper-0 0/1 Pending 0 0s <none> <none> <none> <none>
my-cluster-zookeeper-1 0/1 Pending 0 0s <none> <none> <none> <none>
my-cluster-zookeeper-2 0/1 Pending 0 0s <none> <none> <none> <none>
## 총 시간은 5분 정도 걸린다. 여유를 가지고 기다린다.
$ (⎈ |ubun01:kafka) k get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
my-cluster-entity-operator-559b5d6d89-r7kgd 3/3 Running 0 3m20s 10.233.87.12 ubun20-05 <none> <none>
my-cluster-kafka-0 1/1 Running 0 4m20s 10.233.87.11 ubun20-05 <none> <none>
my-cluster-kafka-1 1/1 Running 0 4m20s 10.233.99.11 ubun20-01 <none> <none>
my-cluster-kafka-2 1/1 Running 0 4m20s 10.233.118.10 ubun20-02 <none> <none>
my-cluster-zookeeper-0 1/1 Running 0 6m32s 10.233.87.9 ubun20-05 <none> <none>
my-cluster-zookeeper-1 1/1 Running 0 6m32s 10.233.99.9 ubun20-01 <none> <none>
my-cluster-zookeeper-2 1/1 Running 1 (4m50s ago) 6m32s 10.233.115.13 ubun20-04 <none> <none>
strimzi-cluster-operator-7c77f74847-jrpq4 1/1 Running 0 7m17s 10.233.87.7 ubun20-05 <none> <none>정상적으로 파드가 설치된다.
(특이하게 'my-cluster-entity-operator'가 설치되는데 머하는 놈인지는 추가 조사가 필요하다.)
카프카 클러스터도 쿠버네티스 리소스로 조회되는 게 편리하다.
$ (⎈ |ubun01:kafka) k get kafka
NAME DESIRED KAFKA REPLICAS DESIRED ZK REPLICAS READY WARNINGS
my-cluster 3 3 True
# jerry @ Jerrys-MacBook-Pro in ~/01.works/01.k8s_switch_helm/kafka on git:master x [5:46:01]
$ (⎈ |ubun01:kafka) k describe kafka my-cluster
(생략)
Kafka:
Config:
default.replication.factor: 3
inter.broker.protocol.version: 3.2
min.insync.replicas: 2
offsets.topic.replication.factor: 3
transaction.state.log.min.isr: 2
transaction.state.log.replication.factor: 3
Listeners:
Name: plain
Port: 9092
Tls: false
Type: internal
Name: tls
Port: 9093
Tls: true
Type: internal
Replicas: 3
Storage:
Type: jbod
Volumes:
Delete Claim: false
Id: 0
Size: 100Gi
Type: persistent-claim
Version: 3.2.0
물론, 다른 리소스들도 자동으로 만들어준다.
## PVC 3개씩 만들어진다.
$ (⎈ |ubun01:kafka) k get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
data-0-my-cluster-kafka-0 Bound pvc-186b66f6-4278-48ac-ae3d-fb9ef1aa4239 100Gi RWO openebs-hostpath 13h
data-0-my-cluster-kafka-1 Bound pvc-8ec56086-991d-4559-9faf-fc8aa0be87d3 100Gi RWO openebs-hostpath 13h
data-0-my-cluster-kafka-2 Bound pvc-b6830794-a970-4b6d-bd73-43452b4509db 100Gi RWO openebs-hostpath 13h
data-my-cluster-zookeeper-0 Bound pvc-56116d18-0c99-480a-9318-900835f08cc3 100Gi RWO openebs-hostpath 13h
data-my-cluster-zookeeper-1 Bound pvc-46da6a24-ee58-46b0-af5f-6b0f48c69d1a 100Gi RWO openebs-hostpath 13h
data-my-cluster-zookeeper-2 Bound pvc-79d851a3-3670-4061-9ab9-db2e86513e60 100Gi RWO openebs-hostpath 13h
## CM(ConfigMap)도 만든다.
$ (⎈ |ubun01:kafka) k get cm
NAME DATA AGE
kube-root-ca.crt 1 13h
my-cluster-entity-topic-operator-config 1 13h
my-cluster-entity-user-operator-config 1 13h
my-cluster-kafka-config 5 13h
my-cluster-zookeeper-config 2 13h
strimzi-cluster-operator 1 13h(Strimzi 오퍼레이터로 클러스터 만들면 어떤 리소스를 만드는지 해당 리스트를 알고 싶은데, 어떻게 조회하는지 잘 모르겠다. helm template 같은 명령어가 있으면 좋겠다)
아쉬운 건 파드 설치에 관한 상세한 옵션을 찾을 수 없는 것이다. 예를 들어 resource requests/limits 설정, pod 보안 관련 설정(podSecruityContext), nodeSelector, tolerations, affinity 관련 설정 등이 필요하면 아마 수동으로 추가해야 하는 불편함이 있다.
CM(ConfigMap)을 보면 현재 클러스터 구성 내역을 조회할 수 있다.
## 클러스터 설정 관련 CM은 'my-cluster-kafka-config' 이다.
## 대략적으로 plain, ssl listener 설정 등을 확인할 수 있다.
$ (⎈ |ubun01:kafka) k describe cm my-cluster-kafka-config
----
PLAIN_9092_0://my-cluster-kafka-0.my-cluster-kafka-brokers.kafka.svc TLS_9093_0://my-cluster-kafka-0.my-cluster-kafka-brokers.kafka.svc PLAIN_9092_1://my-cluster-kafka-1.my-cluster-kafka-brokers.kafka.svc TLS_9093_1://my-cluster-kafka-1.my-cluster-kafka-brokers.kafka.svc PLAIN_9092_2://my-cluster-kafka-2.my-cluster-kafka-brokers.kafka.svc TLS_9093_2://my-cluster-kafka-2.my-cluster-kafka-brokers.kafka.svc
advertised-ports.config:클러스터를 바꾸어 가면서 2~3번 설치를 하였는데 이상없이 매번 잘 된다. 헬름, 오퍼레이터 등을 사용하면 정말 설치는 별 어려움 반복적으로 잘 된다. 쿠버네티스는 이런 부분에서 잘되는 게 만족스럽니다.
설치 관련해서는 쉽게 설치되고 실패없이 설치되는 부분은 만족스럽다. 무엇보다 카프카 설정을 리소스로 확인할 수 있는건 참 좋다. 하지만 헬름 차트에 비하여 설치 옵션 관련 상세한 설정을 확인하기 어려운 부분은 아쉽기는 하다.
이어지는 포스팅에서 카프카 메시지 produce & consume, 페일 오버 테스트를 해 보겠다.
'쿠버네티스 일반' 카테고리의 다른 글
| EKS CSI Driver 설치 (2) | 2022.06.15 |
|---|---|
| Strimzi Kafka Operator - Kafka 토픽 생성 (0) | 2022.06.12 |
| 온프렘 아재의 eks 사용기 (2) | 2022.03.06 |
| 스테이트풀셋 on Kubernetes (0) | 2022.02.06 |
| Pause 컨테이너 정리 (0) | 2022.01.12 |